-
[혼공학습단 9기]혼자 공부하는 데이터 분석 with 파이썬 4주차 미션-2데이터분석 2023. 2. 5. 19:32
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
04-2 분포 요약하기
전체 데이터를 한눈에 보려면 그래프가 효과적입니다. 데이터를 그림으로 요약하는 산점도(scatter plot),히스토그램(histogram),상자 수염그래프(box-and-whisker plot)를 알아보겠습니다.
- 산점도
산점도는 데이터를 흩뿌린 것과 같이 표현하는 그래프입니다.그런데 중첩이 된 걸 잘 알 수가 없습니다.alpha 매개변수로 투명도를 조절할 수 있습니다. x축이 증가함과 동시에 y축도 증가하면 양의 상관관계, x축이 감소하면 y축이 증가하는 것은 음의 상관관계입니다. 산점도는 한 번에 표현하는 특성의 한계가 있습니다.

- 히스토그램
히스토그램은 수치특성을 구간으로 나누어 이를 막대형 그래프로 표현한 것을 말합니다. 각 구간의 데이터 갯수는 도수 or 계급이라고 부릅니다. 히스토그램을 만드는 method는 hist()입니다. 기본적으로 구간을 10개 만들고 bins매개변수를 통해 갯수를 수정할 수 있습니다. numpy에서 histogram_bin_edges()메소드로 각 구간의 경계값도 확인 할 수 있습니다.

- 구간 조정하기
각 구간의 도수가 차이가 많이나면 적은 도수는 보이지 않을 수 있습니다. 위의 경우도 0~250구간에 도수가 너무 커서 나머지 도수들을 볼 수가 없습니다. 이럴 경우 y축을 로그스케일단위로 변경해서 실제 10배차이이지만 보이는 것은 2배차이로 볼 수 있습니다.

히스토그램 그래프는 하나의 특성을 시각적으로 보는데 용이합니다. 하지만 여러 데이터특성을 보기 위해서는 여러 데이터의 히스토그램을 비교해야 합니다. 여러 데이터를 가지고 특성을 비교할 때는 좋은 선택이 아닙니다.
- 상자수염그리기
1.사분위의 25%,75%지점을 밑면, 윗면으로 한 사각형을 그립니다.
2.중간값에 수평선을 그립니다.
3.IQR(제1사분위수에서 제3사분위수까지의 거리)의 1.5배 떨어진 거리에서 가장 멀리 있는 샘플까지 수직선을 긋습니다.
4.이 수직선 밖에서 최솟값과 최댓값까지 데이터를 점으로 표시합니다. 이 영역의 데이터는 이상치입니다.상자 수염 그림은 여러 개의 특성을 시각적으로 비교하기 좋습니다.특히 데이터가 어떤 방향으로 더 많이 늘어져 있는지 한눈에 파악할 수 있습니다.
boxplot 메소드로 상자수염그림을 그리는데 vert매개변수로 수평으로 표현할 수 있고 whis매개변수로 IQR길이를 조절할 수 있습니다. 숫자로 표현할 수 있고(ex) whis=1.5(1.5배) -> whis=10(10배)) 퍼센테이지로도 할 수 있습니다.(ex) whis=(0,100)(0%~100%까지 수염길이))
*위 모든 메소드들은 pandas패키지를 이용하여 사용할 수 있습니다. pandas패키지가 그래프를 그릴때 맷플롯립패키지를 사용하기 때문입니다.
- 기본 미션
ns_book7 남산도서관 대출 데이터에서 1980~2022년 사이에 발행된 도서를 선택하여 다음과 같은 '발행년도' 열의 히스토그램을 그려 보세요.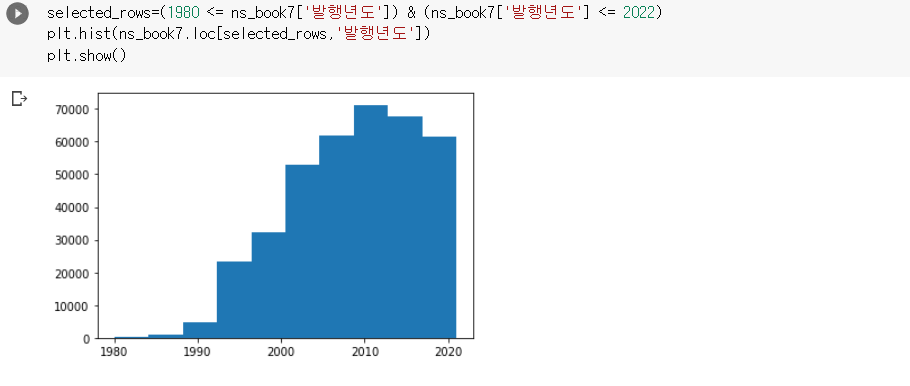
- 선택 미션
평균 : 모든 데이터의 값을 더해 데이터의 갯수로 나눈 값. 즉, 데이터의 대표가 되는 값.
중앙값 : 데이터를 일렬로 나열 했을 때 정확이 50% 위치에 존재하는 데이터의 값.
최솟값 : 데이터 값 중 제일 작은 값.
최댓값 : 데이터 값 중 제일 큰 값.
분위수 : 데이터를 균등한 기준으로 나누는 기준점. 2분위는 중앙값을 기준으로 나눈 것이고 가장 많이 쓰는 4분위는 데이터를 일렬로 세웠을 때, 25%지점, 50%지점, 75%지점 100%지점을 기준으로 합니다.
분산 : 데이터가 평균으로 부터 얼마나 떨어져 있는지의 정도를 나타내는 데이터입니다.
(평균-데이터의 전체 합)^2/전체데이터 수로 구합니다.
표준 편차 : 분산의 제곱근으로 분산이 제곱으로 계산되기에 평균에서의 거리에 따라 변동사항이 커 해석이 어려울 경우가 있습니다. 이럴 경우 표준 편차를 이용합니다.
최빈값 : 데이터 중 가장 많이 같은 값을 가지고 있는 값.
'데이터분석' 카테고리의 다른 글
[혼공학습단 9기]혼자 공부하는 데이터 분석 with 파이썬 6주차 미션 (0) 2023.02.18 [혼공학습단 9기]혼자 공부하는 데이터 분석 with 파이썬 5주차 미션 (0) 2023.02.09 [혼공학습단 9기]혼자 공부하는 데이터 분석 with 파이썬 4주차 미션-1 (0) 2023.02.05 [혼공학습단 9기]혼자 공부하는 데이터 분석 with 파이썬 3주차 미션 (0) 2023.01.24 [혼공학습단 9기]혼자 공부하는 데이터 분석 with 파이썬 2주차 미션 (0) 2023.01.15